

Ο μαγικός κόσμος της κρυπτογράφησης (2) – Εργαλεία Ανάλυσης Συχνότητας
Στο πρώτο μέρος της σειράς άρθρων για την κρυπτογραφία, είδαμε τον κώδικα του Καίσαρα (Caesar Cipher). Καταλάβαμε ότι δεν είναι ασφαλής μέθοδος κρυπτογράφησης και οποιοσδήποτε με μερικές δοκιμές μπορεί να καταλάβει τη μετατόπιση που θα πρέπει να κάνει στο αλφάβητο για να “ξεκλειδώσει” ένα μήνυμα. Στο άρθρο αυτό θα δούμε μια πολύ ενδιαφέρουσα τεχνική για να “μαντέψουμε” την κωδικοποίηση αντικατάστασης που χρησιμοποιήθηκε σε ένα κρυπτογραφημένο μήνυμα. Η μέθοδος χρησιμοποιεί πίνακες ανάλυσης συχνότητας εμφάνισης γραμμάτων (ή/και λέξεων).
Ας το δούμε μαζί αναλυτικά…
Θα προσπαθήσουμε να “ξεκλειδώσουμε” ένα μήνυμα που έχει κρυπτογραφηθεί με τυχαία αντικατάσταση των γραμμάτων του αλφαβήτου (random substitution). Όπως είδαμε στο πρώτο μέρος, με αυτήν την τεχνική κρυπτογράφησης δε μπορούμε να οδηγηθούμε στο κανονικό μήνυμα με δοκιμές. Στην πραγματικότητα είναι πιθανότερο να κερδίσουμε το τζόκερ παρά να πετύχουμε τη λύση – αποκρυπτογράφηση του μηνύματος. Κάτι όμως που φαντάζει τόσο αδύνατο, μπορεί να γίνει δυνατό κάνοντας χρήση των εργαλείων ανάλυσης συχνοτήτων γλώσσας (frequency-analysis). Με τον όρο ανάλυση συχνότητας γλώσσας περιγράφεται η μελέτη της συχνότητας των γραμμάτων (ή ομάδας γραμμάτων) σε ένα κρυπτογράφημα (ciphertext). Η τεχνική αυτή εφαρμόζεται σε περιπτώσεις όπου το πρωτότυπο κείμενο (plaintext) έχει κρυπτογραφηθεί με κάποια μέθοδο Μονοαλφαβητικής Αντικατάστασης, δηλαδή κάθε ένα γράμμα του πρωτότυπου αντικαθίσταται με μόνο έναν άλλο χαρακτήρα.
Για παράδειγμα, το πινακάκι που ακολουθεί απεικονίζει τα ποσοστά εμφάνισης και των 26 γραμμάτων του αλφαβήτου, στην Αγγλική Γλώσσα:
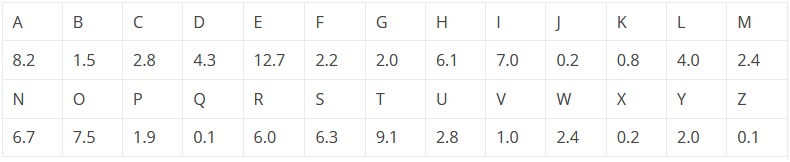
Αν ταξινομήσουμε κατά φθίνουσα σειρά συχνότητας εμφάνισης, θα πάρουμε τον πίνακα που ακολουθεί:
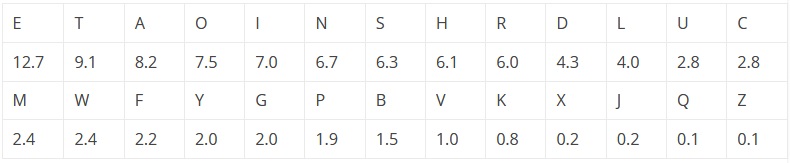 Όπως μπορούμε να δούμε, το γράμμα που εμφανίζεται συχνότερα είναι το Ε (12,1%), στη συνέχεια το Τ(9,1%), κ.ο.κ.
Όπως μπορούμε να δούμε, το γράμμα που εμφανίζεται συχνότερα είναι το Ε (12,1%), στη συνέχεια το Τ(9,1%), κ.ο.κ.
Όταν λοιπόν πάρουμε ένα μήνυμα (στο παράδειγμά μας, στην Αγγλική Γλώσσα) που έχει κρυπτογραφηθεί με τη μέθοδο της τυχαίας αντικατάστασης, θα αναζητήσουμε σε αυτό τους εμφανιζόμενους χαρακτήρες και το πόσες φορές εμφανίζονται. Προφανώς τα γράμματα που εμφανίζονται περισσότερες φορές θα αντιστοιχούν σε κάποια από τα Ε,Τ,Α (δηλαδή τα πιο συχνά εμφανιζόμενα στην Αγγλική Γλώσσα).
Προφανώς ακόμη σας μπερδεύει διαδικασία… αλλά η σελίδα της Ώρας του Κώδικα (Code.org), μας παρέχει μια ακόμη εξαιρετική εφαρμογή για να δοκιμάσουμε τα παραπάνω. Κάντε κλικ εδώ, και πριν ξεκινήσετε τις δοκιμές επιλέξτε από την πάνω αριστερή γωνία το δύσκολο μήνυμα (Message Sample – Hard). Επίσης από τη μέθοδο κρυπτογράφησης, επιλέξτε την τυχαία (Random). Δείτε την παρακάτω εικόνα για να κάνετε τις ρυθμίσεις:
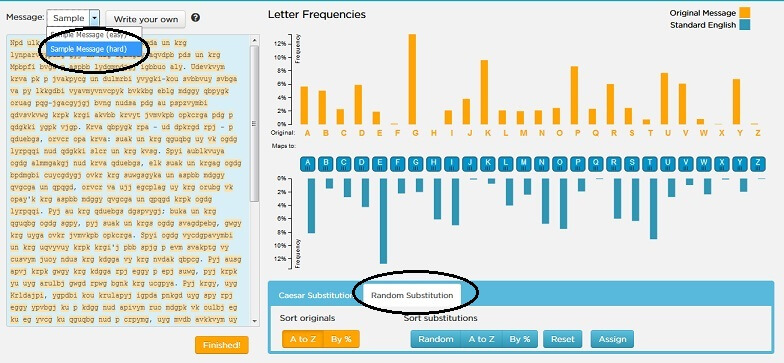
Ταξινομήστε τα γράμματα που εμφανίζονται στο κείμενο με βάση τη συχνότητα εμφάνισής τους (πορτοκαλί %) και κάντε το ίδιο για να δείτε και τη ανάλυση συχνότητας εμφάνισης των γραμμάτων στην Αγγλική γλώσσα (μπλε %):

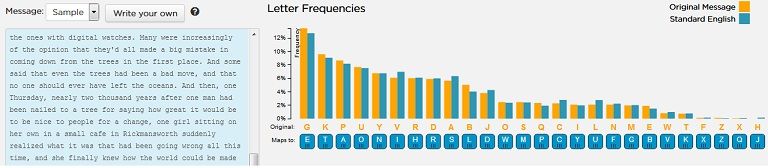
Αφού πατήσετε την ταξινόμηση θα δείτε πλέον κάτι τέτοιο:

Τι σημαίνουν αυτά τα διαγράμματα;. Βλέπουμε ότι το πιο συχνά εμφανιζόμενο γράμμα στο κέιμενό μας είναι το G. Στη συνέχεια, το Κ, το P, το U, κλπ.
Αντίστοιχα στην Αγγλική γλώσσα τα πιο συχνά εμφανιζόμενα, όπως είδαμε και παραπάνω είναι τα Ε, Τ, Α, Ο, κλπ.
Η λογική λοιπόν λέει πως θα μπορούσα να αντιστοιχίσω στο κρυπτογραφημένο μήνυμα, όπου G, το Ε, όπυ Κ το Τ, κ.ο.κ.
Προσοχή! Αυτό δεν είναι απόλυτο, και εξαρτάται από το είδος του κειμένου (π.χ. άλλο ένα λογοτεχνικό απόσπασμα, άλλο ένα επιστημονικό άρθρο). Επίσης ένα μικρό κείμενο δε μπορεί να αποδώσει με ικανοποιητική ακρίβεια τη συχνότητα εμφάνισης των γραμμάτων. Όπως και να’χει όμως είναι ένα όπλο στα χέρια του αποκρυπτογράφου του μηνύματος. Πραγματικά έχει μεγάλο ενδιαφέρον να δοκιμάσετε να αποκρυπτογραφήσετε το μήνυμα μέσω της εφαρμογή του Code.org.
Ας δούμε πως θα το κάνετε. Ας υποθέσουμε πως θέλουμε να αντιστοιχίσουμε στο G (του κρυπτογραφημένου μηνύματος), το Ε. Θα πάρετε με το ποντίκι σας το Ε και θα το σύρετε δίπλα στο G. Αν το κάνετε, στο κείμενό σας όπου G θα βλέπετε πλέον το Ε:
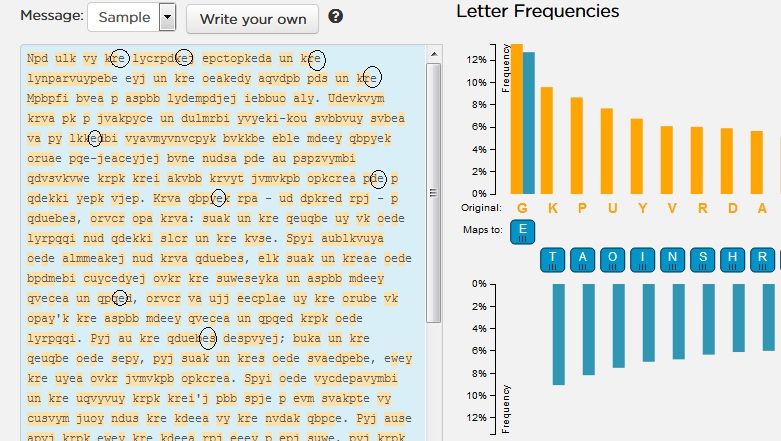
Με την ίδια λογική κάνετε αντικαταστάσεις και των υπόλοπων γραμμάτων. Η ανάλυση συχνοτήτων σας επιτρέπει να κάνετε πλέον λογικούς συσχετισμούς, και όχι δοκιμές στην τύχη. Φυσικά μπορεί να αλλάξετε τις αντικαταστάσεις πολλές φορές μέχρι να καταφέρετε κάποιο αποτέλεσμα. Η διαδικασία εξακολουθεί να είναι επίπονη και χρονοβόρα, εξάλλου πρόκειται για κάτι πολύ σπουδαίο, την αποκρυπτογράφηση ενός μηνύματος! Παρόλα αυτά ο χρόνος για να αποκρυπτογραφηθεί το συγκεκριμένο μήνυμα, είναι ελάχιστος σε σύγκριση με την προσπάθεια δοκιμών που δε θα το έλυνε ποτέ! Μόλις καταλάβετε πως δουλεύει θα δείτε ότι δε θα χρειαστείτε περισσότερο από 5 λεπτά. Αξίζει να το προσπαθήσετε πριν δείτε τη λύση:
Αν το καταφέρατε μόνοι σας σας αξίζει ένα μεγάλο μπράβο και μπορείτε πλέον να δοκιμάσετε με ένα δικό σας κείμενο. Πατήστε το κουμπί Write your own (επάνω δεξιά), πατήστε Random, και δοκιμάστε να το αποκρυπτογραφήσετε.
Όλα όσα είδαμε και καταφέραμε οφείλονται στην ύπαρξη των εργαλείων ανάλυσης συχνοτήτων. Εμείς είδαμε εφαρμογές για την Αγγλική γλώσσα, λόγω της ύπαρξης των διαδραστικών εφαρμογών για να κάνουμε τις δοκιμές μας. Για την Ελληνική θα έπρεπε να έχουμε τον πίνακα συχνοτήτων των γραμμάτων του αλφαβήτου για την Ελληνική γλώσσα. Κατόπιν αρκετού ψαξίματος βρήκα πως τα πιο συχνά εμφανιζόμενα γράμματα στην Ελληνική γλώσσα είναι τα Α, Ο, Τ, Ε, Ν, Ι, Π, Ρ, Σ, Μ, Υ, Κ, ακολουθούν τα Λ, Η, Γ, Δ, Ω, Χ, Θ, και τα πιο σπάνια εμφανιζόμενα είναι τα Φ, Β, Ξ, Ζ και Ψ. Με βάση τα στοιχεία αυτά, μπορούμε πλέον να αποκρυπτογραφούμε κείμενα και στην ελληνική γλώσσα. Σας υπενθυμίζω πως όλα αυτά εφαρμόζονται σε περιπτώσεις όπου το πρωτότυπο κείμενο έχει κρυπτογραφηθεί με μέθοδο Μονοαλφαβητικής Αντικατάστασης, δηλαδή κάθε ένα γράμμα του πρωτότυπου αντικαθίσταται με μόνο έναν άλλο χαρακτήρα.
Μέχρι το επόμενο άρθρο… δοκιμάστε τις δικές σας κρυπτογραφήσεις και αποκρυπτογραφήσεις!!!



